저번 게시글에서 sampleDB를 이용해 집계함수의 사용에 대해 살펴보았습니다.
Sample DB 설정 방법은 다음 링크를 참조하세요. (https://m-datastudy.tistory.com/5)
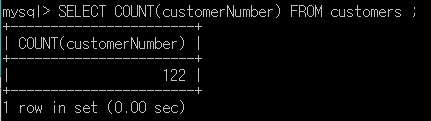
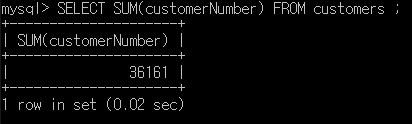
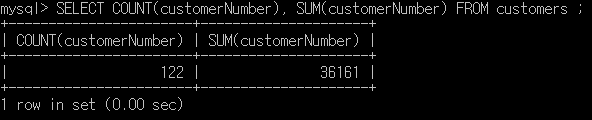
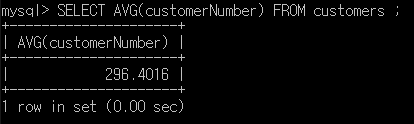
이번에는 마찬가지로 SELECT ~ FROM 쿼리(구문)에 사용할 수 있는 집계함수 외의 함수를 알아볼것입니다. 저번 게시물 (https://m-datastudy.tistory.com/10)를 보신 분들은 이제 레코드의 개수나 숫자로 된 레코드 값의 합, 평균 등을 알아볼 수 있고, 특정 기준에 따라 레코드를 묶을 수도 있습니다.
먼저 함수는 저번과 이번 게시물에 적힌 것보다 훨씬 많습니다. 지금 쓰려는 것은 그 중 기본적이라고 생각되는 함수인것입니다.
1. SUBSTRING('문자열' , offset, limit)
SUBSTRING 함수는 문자열에서 원하는 부분만 뽑아내는 함수입니다.
FROM 구문이 반드시 필요하지는 않습니다. 다음과 같이 사용합니다.
-> SELECT SUBSTRING('문자열' , offset, limit);
-> SELECT SUBSTRING('2019-03-19' , 6, 2);
또한 모든 함수는 반드시 정해진 인자에 맞춰서 사용해야만 합니다. 인자란 ('문자열', offset, limit)의 부분을 의미합니다.
1. '문자열' 부분은 우리가 뽑아내고싶은 글자가 있는 문장이나 긴 텍스트를 넣습니다.
2. offset 부분은 저번에 살펴보았던 LIMIT~OFFSET~ 구문처럼 어디서 부터 텍스트를 뽑아낼 것인지 숫자로 정합니다.
예를 들어 '2019-03-19' 문자열에서 첫번째 글자인 '2'가 1번째 글자이고 '0'이 2번째, '1'이 3번째, '9'가 4번째 글자입니다.
3. limit 부분은 몇글자를 뽑아낼지 정합니다.

정리하자면, SELECT SUBSTRING('2019-03-19' , 6, 2); 쿼리는 '2019-03-19'라는 문장의 6번째 글자부터 2글자를 찾아 출력하라는 뜻입니다. 결과값은 '03'이 됩니다. 작은 따옴표 안의 모든 글이 텍스트입니다. 따라서 ' - ' 또한 텍스트입니다.
2. TRIM('문자열')
TRIM 함수는 문자열 앞 뒤에 있는 공백을 제거합니다. ' 서울특별시 '를 함수 처리 할 경우 '서울특별시'로 출력됩니다.
단, 문자 내부의 공백은 제거되지 않습니다. substring처럼 반드시 FROM이 필요하지는 않습니다.
-> SELECT TRIM(' 문자열 ');

3. CHAR_LENGTH('문자열'), OCTET_LENGTH('문자열')
CHAR_LENGTH 함수는 문자열의 길이. 즉, 글자수를 알려주는 함수입니다. 다음과 같이 사용합니다.
-> SELECT CHAR_LENGTH('문자열');
-> SELECT CHAR_LENGTH('123');

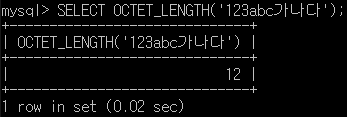
OCTET_LENGTH 함수는 문자열의 byte 수. 즉, 용량을 알려주는 함수입니다.
일반적으로 문자 하나 당 숫자 및 영어는 1byte. 한글은 2byte입니다. 다음과 같이 사용합니다.
-> SELECT OCTET_LENGTH('문자열');
-> SELECT OCTET_LENGTH('123abc가나다');
4. ROUND(컬럼명/숫자, 반올림위치)
ROUND 함수는 반올림해주는 함수입니다. 어느 위치에서 반올림 할 지도 직접 정할 수 있습니다.
mySQL에서는 2가 소숫점 둘째 자리로 반올림해줍니다. 1이 첫째 짜리로, -1이 1의 자리, -2가 10의 자리로 반올림해주는 식입니다. 소숫점 둘째 자리에서 반올림 해주는 것이 아니라 결과값이 소숫점 둘째자리로 출력됩니다.
-> SELECT ROUND(컬럼명/숫자, 반올림 위치);
-> SELECT ROUND(컬럼명, 2) FROM 테이블명;
-> SELECT ROUND(5961.6651, 2);

5. CONCAT('문자열1'/컬럼명, '문자열2'/컬럼명)
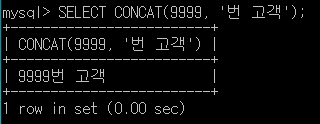
CONCAT 함수는 여러개의 문자열을 합칠 수 있는 함수입니다. 앞 뒤 글자가 합쳐집니다. 컬럼명일 경우엔 자료형이 숫자형 혹은 문자형이어야 합니다.
컬럼명 + 문자열도 가능합니다. 예를 들어,
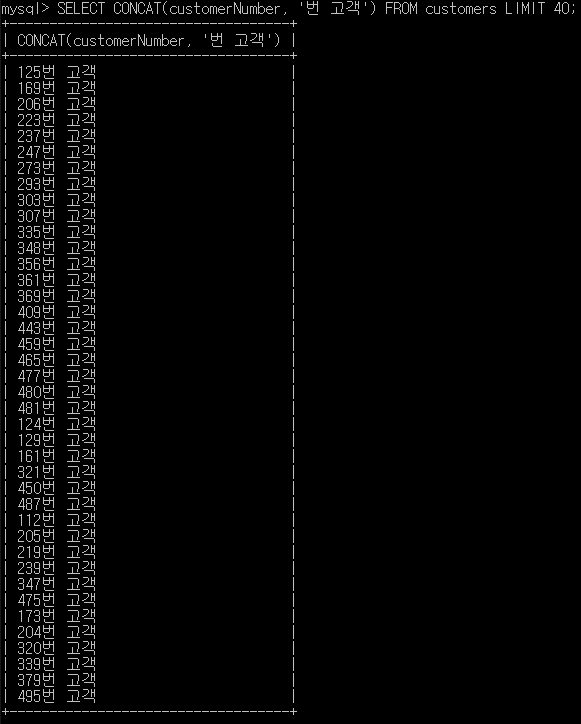
-> SELECT CONCAT(customerNumber, '번 고객') FROM customers;
일 경우에, 컬럼 내의 모든 레코드의 뒤에 '번 고객'이 합쳐져 출력됩니다.
'SQL > mySQL' 카테고리의 다른 글
| [mySQL] 집계함수: COUNT, SUM, AVG, GROUP BY (0) | 2020.02.04 |
|---|---|
| [mySQL] SELECT 구문의 확장. WHERE . (0) | 2020.01.17 |
| [mySQL] SELECT - FROM 구문을 이용해 데이터 불러오기 (0) | 2019.12.04 |
| [mySQL] 학습용 DB구축하기 (0) | 2019.12.04 |
| [mySQL] Windows 10 mySQL server 설치 (0) | 2019.12.04 |